
목차
Shallow Nueral Network
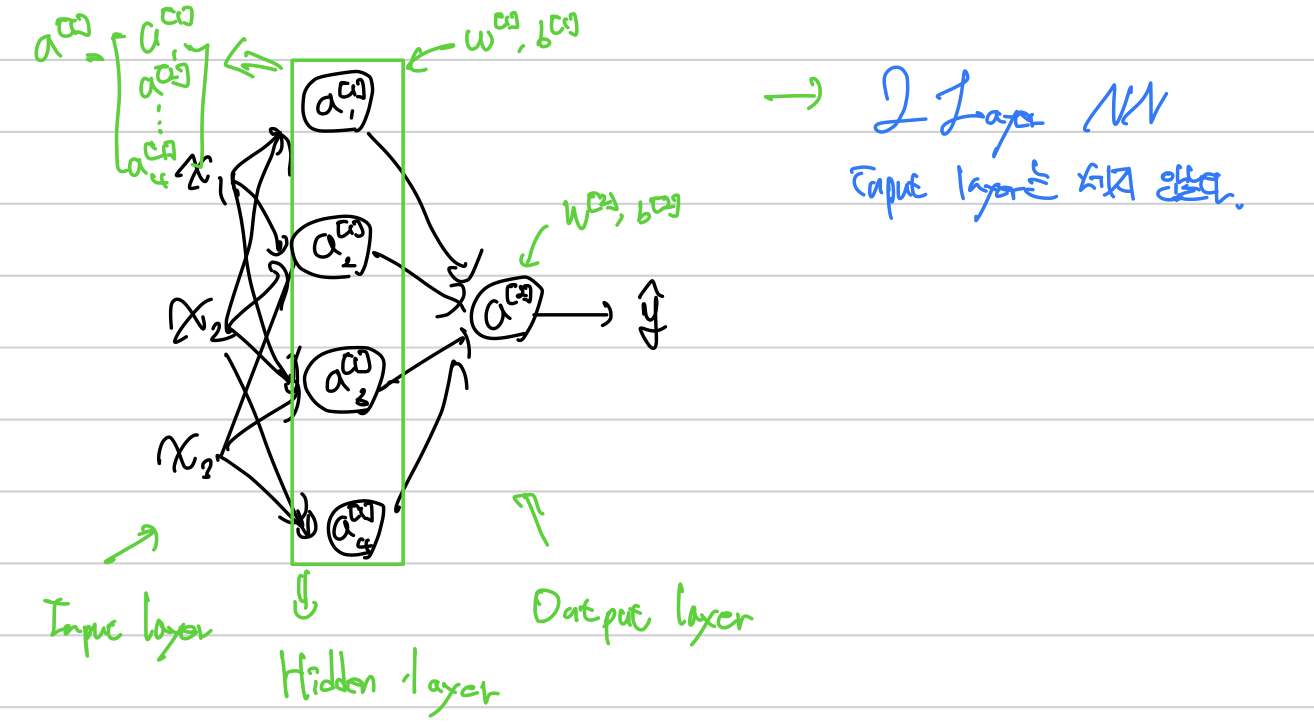
각 layer를 구분하기 위해
$$ a^{[l]} $$ 윗첨자를 붙여 구분한다.
각각의 유닛을 구분하기 위해
$$ a_{u} $$ 아랫첨자를 붙여 구분한다.
하나하나의 unit을 살펴보면 하나하나가 이렇게 구성되어있다.

하나하나의 unit이 각각 로지스틱 회귀를 구성하고 있다.
Vectorizing
이것들을 벡터로 나타내면 다음과 같다.

이 하나하나의 훈련예제(training example)들을 한번에 계산 해 볼 것이다.
각각의 훈련예제는 윗첨자 (m)으로 구분한다.
$$ z^{(m)} $$

Activation Function
- 입력을 변환해주는 함수
sigmoid function
$$ A^{[l]} = \sigma(Z^{[l]}) $$
$$ a = \frac{1}{1+e^{-z}} $$

tanh function
$$ a = tanh(z) = \frac{e^{z}-e^{-z}}{e^{z}+e^{-z}} $$

0을 중심으로 하는 함수. sigmoid와 아주 유사하지만, 대부분의 상황에서 sigmoid보다 성능이 잘 나온다.
ReLU ( Reflect Linear Unit )
$$ a = max(0, z) $$

가장 많이 쓰이는 함수
Leaky ReLU
$$ a = max(0.01z, z) $$

Why use Non-Linear Activation Function
왜 비선형함수여야 할까를 알아보기 위해 선형함수를 적용할때를 알아보자
$$ g(z) = z $$
$$ z^{[1]} = a^{[1]} = W^{[1]}X + b^{[1]} $$
$$ z^{[2]} = a^{[2]} = W^{[2]}a^{[1]} + b^{[1]} $$
$$ z^{[2]} = a^{[2]} = W^{[2]}W^{[1]}X + W^{[2]}+b^{[2]} + b^{[1]} $$
$$ W^{[2]}W^{[1]} = W^{'}, W^{[2]}+b^{[2]} + b^{[1]} = b^{'} $$
$$ z^{[2]} = W^{'}X + b^{'} $$
선형함수를 적용하면, 활성화 함수를 적용하는 의미가 아예 사라진다. 그래서 우리는 비선형 함수를 사용ㅎ나다.
Random initialization
이때가진 W가중치의 값을 0으로 초기화 했었는데, 사실 이러면 큰 문제가 생긴다.

첫번째 레이어의 유닛들이 결국 같은 값을 가지게 된다.
그래서 W가중치의 값을 랜덤하게 초기화 해주는것이 필요하다.
W = np.random.randn((2, 2))*0.01
b = np.zeros((2, 1))0.01을 곱해주는 이유
sigmoid, tanh를 떠올려보자.

값이 클때는 미분값이 매우 작아진다.
미분값이 작다는것은, backpropagation때 더하거나, 빼는 값이 작아진다는것으로 결국 학습을 느리게 하는 요소가 된다.
당연하게도 sigmoid, tanh에서만 적용되는 말이다.
따로 부족한 부분이나 틀린점, 오타 지적은 댓글로 부탁드려요!
'개발 기록 > Google ML Bootcamp' 카테고리의 다른 글
| 구글 머신러닝 부트캠프 2주차(1/3) (0) | 2022.09.02 |
|---|---|
| 구글 머신러닝 부트캠프 1주차(4/4) (2) | 2022.08.24 |
| 구글 머신러닝 부트캠프 1주차(2/4) (0) | 2022.08.03 |
| 구글 머신러닝 부트캠프 1주차(1/4) (0) | 2022.08.03 |